Simple-BEV: What Really Matters for Multi-Sensor BEV Perception?
Adam W. Harley Zhaoyuan Fang Jie Li Rares Ambrus Katerina Fragkiadaki
ICRA 2023
Abstract
Building 3D perception systems for autonomous vehicles that do not rely on high-density LiDAR is a critical research problem because of the expense of LiDAR systems compared to cameras and other sensors. Recent research has developed a variety of camera-only methods, where features are differentiably "lifted" from the multi-camera images onto the 2D ground plane, yielding a "bird's eye view" (BEV) feature representation of the 3D space around the vehicle. This line of work has produced a variety of novel "lifting" methods, but we observe that other details in the training setups have shifted at the same time, making it unclear what really matters in top-performing methods. We also observe that using cameras alone is not a real-world constraint, considering that additional sensors like radar have been integrated into real vehicles for years already. In this paper, we first of all attempt to elucidate the high-impact factors in the design and training protocol of BEV perception models. We find that batch size and input resolution greatly affect performance, while lifting strategies have a more modest effect—even a simple parameter-free lifter works well. Second, we demonstrate that radar data can provide a substantial boost to performance, helping to close the gap between camera-only and LiDAR-enabled systems. We analyze the radar usage details that lead to good performance, and invite the community to re-consider this commonly-neglected part of the sensor platform.
Overview
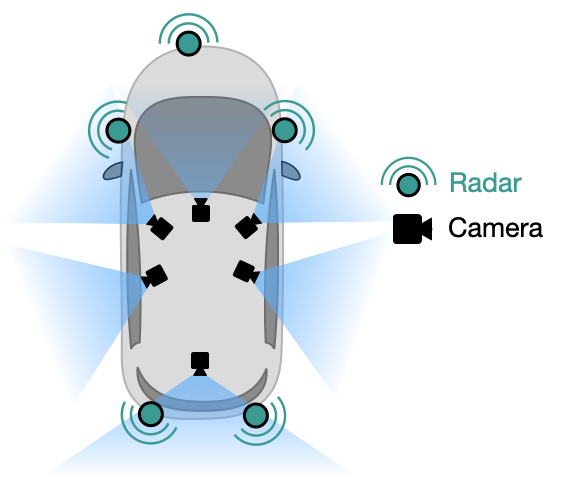
To perform driving-related tasks, autonomous vehicles need at least a "bird’s eye view" representation of the 3D space surrounding the vehicle. The challenge is to acquire the bird’s eye view representation from sensors mounted on the vehicle itself, In this work, we present a simple baseline for this perception problem, which is more accurate, faster, and requires fewer parameters, than the current state-of-the-art.
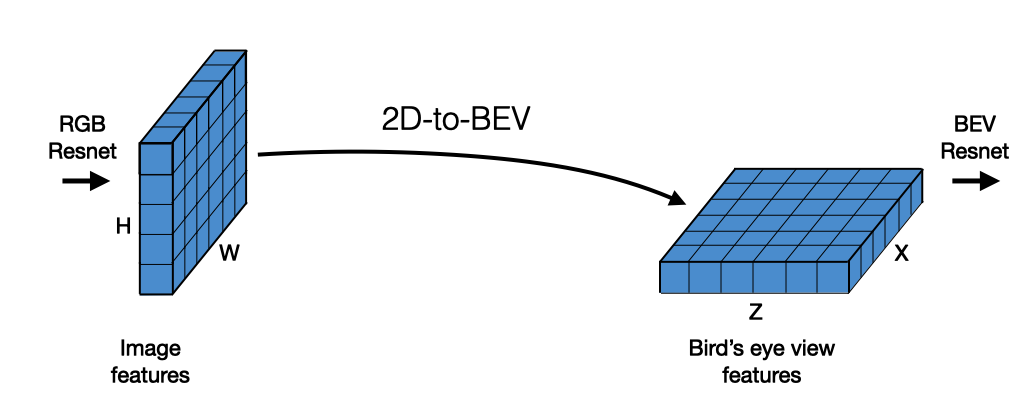
Recent work has focused on innovating new techniques for "lifting" features from the 2D image planes to the BEV plane, delivering the final outputs using cameras alone.
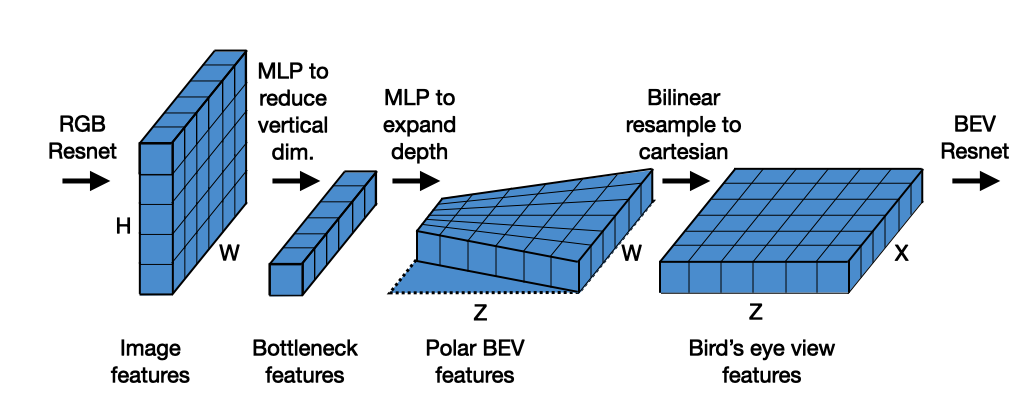
T. Roddick and R. Cipolla. Predicting semantic map representations from images using pyramid occupancy networks. CVPR 2020 |
J. Philion and S. Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3D. ECCV 2020. |
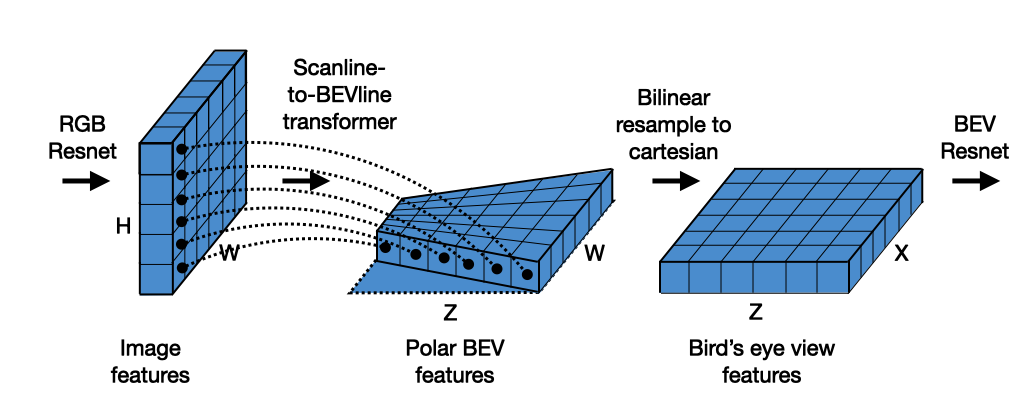
A. Saha, O. M. Maldonado, C. Russell, and R. Bowden. Translating images into maps. ICRA 2022. |
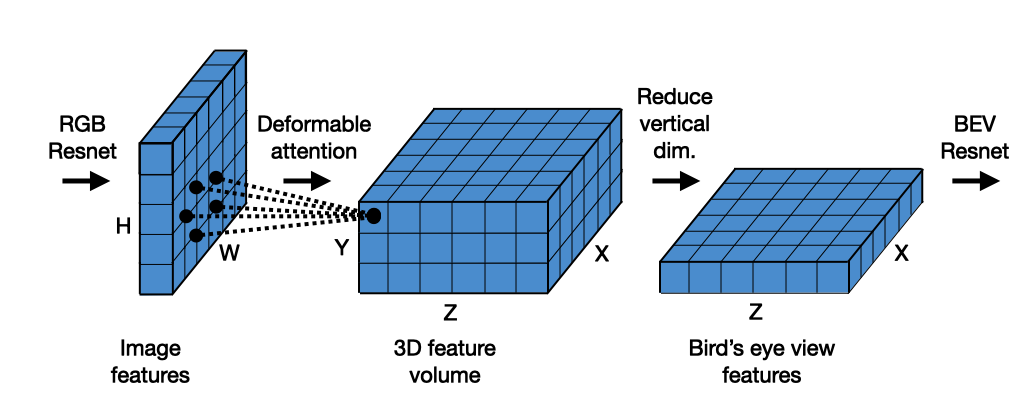
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai. Bevformer: Learning bird’seye-view representation from multi-camera images via spatiotemporal transformers. ECCV 2022. |
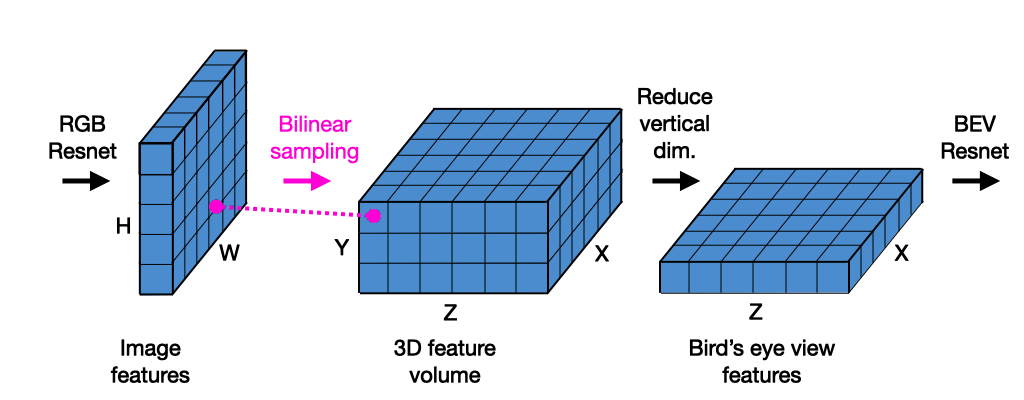
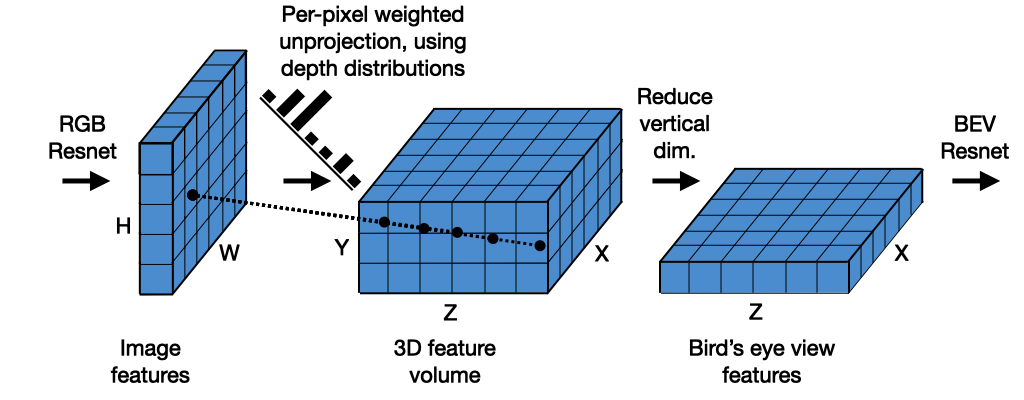
In our proposed baseline model, we take a parameter-free approach, which is: we take the 3D coordinate of a voxel, project it into the image feature map, and bilinearly sample there. Other aspects of our model, in terms of the 2D and BEV CNNs, are similar to related work.
|
|
As we establish this new simple baseline, we also take the opportunity to question idea of relying on cameras alone, instead of fusing readily-available metric information from, for example, radar. We have seen prior work report that the radar data in nuScenes is perhaps too sparse to be useful.
Visualizing the data (on the left), we can see it is indeed much sparser than LiDAR, but it gives some hints about the metric scene structure, which is very difficult to get from RGB alone. |
Hypothesizing that some metric information is better than none, we implement a very simple strategy to fuse the radar information with the RGB feature volume: we rasterize the radar data into an image matching the BEV dimensions, and simply concatenate it as an additional channel.

Our experiments show that incorporating radar in this way provides a substantial boost in accuracy.
Results
Please see the paper for quantitative results and analysis. Here, we show video visualizations of the performance.
RGB-only model
Top-left: our predictions. Top-right: ground truth. Bottom half: camera input.
RGB+radar model
Top row (in order): LiDAR (for reference), radar (input), our predictions, ground truth. Bottom half: camera input.
A clear avenue for future work is to integrate information across time, so that the predictions are less sensitive to momentary occlusions.
Paper

Bibtex
@inproceedings{harley2023simple,
author = {Adam W. Harley and Zhaoyuan Fang and Jie Li and Rares Ambrus and Katerina Fragkiadaki},
title = {Simple-{BEV}: What Really Matters for Multi-Sensor BEV Perception?},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2023}
}